Integration Link Troubleshooting
This article helps you solve some issues that you may encounter while working with Integration Links.
Integrating with External Systems (Loosely Coupled Integration)
Problem
Let's assume you want to integrate FNZ Studio with another system, e.g. a core banking system. How can you make the integration robust towards change while keeping complexity to a minimum?
Solution
Let's assume you are building an online banking system that allows customers to deposit money into their account from another bank. To perform this, our application has to be integrated with the back-end financial system that manages fund transfers.
Tightly-Coupled Integration: Drawbacks
The easiest way to connect the two systems is through TCP/IP. To keep things simple, let's assume that the remote function that deposits money into a person's account takes only the person's name and the dollar amount as parameters.
The following script implements that function. It opens a socket and sends the amount and account name to the target bank:
// get the target host by name
Host host=DNS.getHostByName("www.thebank.com");
// retrieve the IP address
Address adr=host.getAddress(9090);
// open a socket for TCP communication
Socket socket= new Socket(Socket.STREAM, PortocolType.TCP);
socket.connect(adr);
// amount
int amount=1000;
// account
String account="Moe Szyslak";
// send amount and name
socket.send(Integer.getBytes(amount));
socket.send(String.getBytes(account));
// terminate transmition
socket.close();
The minimalistic integration scenario above is fast and cheap, but it results in a very tightly coupled system because the two participating peers make a lot of assumptions about each other:
- Platform technology — internal representation of number and objects
- Location — hardcoded host address
- Time — all components have to be available at the same time
- Data format — the list of parameters and their types must match
Assumptions are problematic. The location of the peer system, for example, is fixed in the code. What if the call to www.thebank.com fails, or we want to send the message to more than one peer? A change of scenario would also need a change in the code.
Another example of a potential issue in the scenario above is the message format. TCP/IP is a very basic communication protocol which relies on byte streams. It doesn't deal with internal memory representation of numbers. Many 32-bit systems send 4 bytes for an integer; a 64-bit system would be urged to read 8 bytes to reconstruct the same integer. PC systems store numbers in little-endian format while others use big-endian.
The value 1000(DEC)=11'1110'1000(BIN) can be interpreted using 32-bit little-endian as 23+25+26+27+28+29 = 1000. A 32-bit big-endian system would reconstruct this to 231+230+229+228+227+225 = 4,194,304,000, a very big number. A 64-bit big-endian system would make Moe Szyslak richer than C. Montgomery Burns!
In sum, the fewer the number of assumptions, the looser the coupling between the systems and the more robust the integration is.
Loosely-Coupled Integration
To make the integration loosely coupled, we must get rid of assumptions:
- Use a platform-independent, self-describing data format, for example XML.
- Use a messaging infrastructure that provides a logic address for each peer. Thus, the peers don't need to know each other.
- If the messaging infrastructure queues messages that have not been received, the communication will be time-independent.
Removing the dependencies between the systems makes the overall solution more tolerant to change: This is the key benefit of loose coupling. The main drawback, on the other hand, is the additional complexity.
This is where FNZ Studio's Integration Link engine comes in. This infrastructure makes exchanging data between systems as simple as the example code above, while reducing the number of assumptions we have to make for the communication. We reach a high degree of loose coupling without complex scripting.
An example of an Integration Link handling money transfer is show in the next figure.
![]()
- The Money-Transfer link receives the transfer messages from FNZ Studio.
- The next step converts the received message to XML (the format required by the transfer service).
- The XML structure is transmitted to the target system using a secure REST call.
- The response's format is XML; the final step in the link converts the XML document back to an FNZ Studio Data Entity.
Splitting Messages (Splitter)
Problem
Many messages passing through an integration solution consist of multiple elements. For example, an order placed by a customer consists of more than just a single item. Each item may need to be handled by a different inventory system. Thus, we need to find an approach to process a complete order, but treat each item contained in the order individually.
Solution
Use a Splitter to break out the composite message into a series of individual messages, each containing data related to one item. The Splitter publishes one message for each single element (or subset of elements) from the original message.
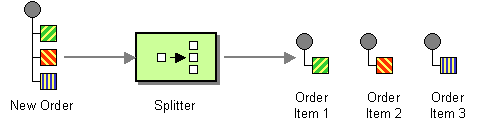
In FNZ Studio, create an Integration Link which uses the Splitter component. The Splitter component uses the 'splitter script' to create a list of single items that must be processed, and the 'aggregation script' to aggregate the result of processing the single items.
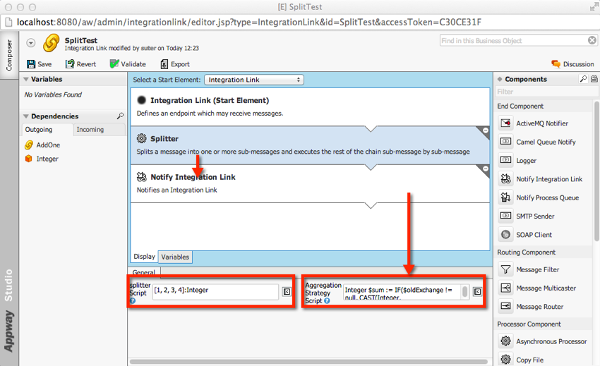
In the example above, the splitter script creates a list of numbers.
[1,2,3,4]:Integer
Each number is processed by the subsequent elements of the Integration Link. The result of processing is sent back to the aggregation script.
Integer $sum := IF($oldExchange != null, CAST(Integer, $oldExchange.getIn().getBody()), 0);
Integer $i := CAST(Integer, $newExchange.getIn().getBody());
Return $sum := $sum + $i;
The script takes the 'last' aggregated value (line 1) and the current / new value (line 2), and builds the sum of both (line 3).
The sum (which is the result of the aggregation) is used as the new last value for the next aggregation step.
The aggregation script is called four times — once for each item in the items collection. This is what the old and new exchanges look like in each iteration:
Iteration 1:
$oldExchangeis null,$newExchangecontains the value 1
Iteration 2:
$oldExchangecontains the value 1 (result of adding 0 + 1)$newExchangecontains the value 2
Iteration 3:
$oldExchangecontains the value 3 (result of adding 2 + 1)$newExchangecontains the value 3
Iteration 4:
$oldExchangecontains the value 6 (result of adding 3 + 3)$newExchangecontains the value 4
The result of Iteration 4 is 10, which is the overall result that the Integration Link returns.
Performing Cross-Node Integration
Problem
Due to architectural constraints, you may need to put in place two separate FNZ Studio servers. Some of the business processes, however, span across the two nodes. What is the best approach to integrate them?
Solution
In this example, you will see two nodes: Node A and Node B. Communication between the servers requires a service bus, like a JMS server, or an ActiveMQ server. The high-level communication flow is illustrated in the diagram below.
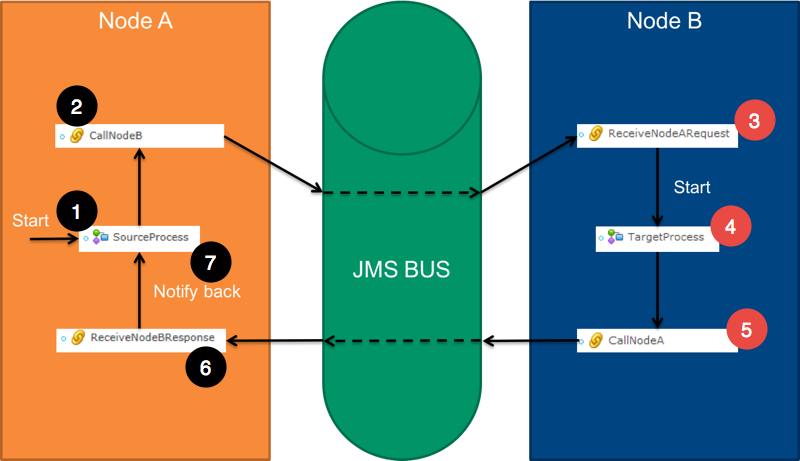
The user starts the Source Process manually on Node A. At some point in the process, Node A calls Node B via an Integration Link ("CallNodeB"). The call publishes a message to the service bus.
Node B has a listening Integration Link ("ReceiveNodeARequest") that picks up the message published by Node A. The "ReceiveNodeARequest" Integration Link then starts the Target Process on Node B automatically.
The Target Process, at some point, executes a call to Node A via another Integration Link ("CallNodeA"). This call publishes a message to the service bus.
Node A also has a listening Integration Link ("ReceiveNodeBResponse") that picks up the message published by node B, and notifies the Source Process.
Source Process
The following image illustrates how the Source Process could be constructed.
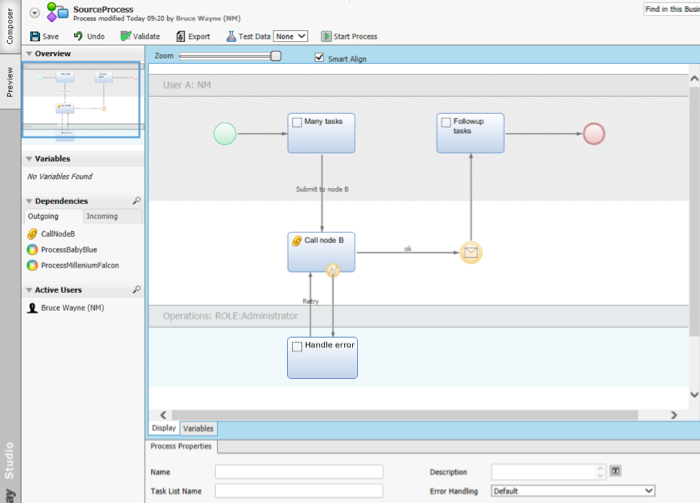
The user initially performs a wide variety of tasks, which at a certain point initiate the Call node B integration flow.
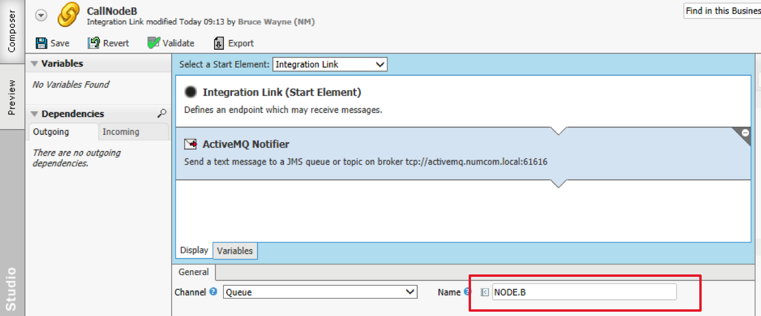
Call Node B Integration Link
In order to make sure the Call node B task can be properly responded to, Node A needs to send the ProcessInstanceId() in the message payload when calling Node B. This can be achieved using the configuration settings Message = ProcessInstanceId() and Integration Link = CallNodeB.
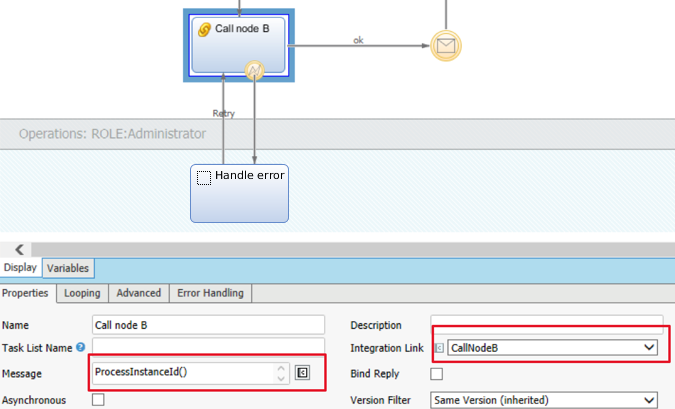
In the Integration Link configuration settings, specify the queue name of the JMS/Active MQ queue that receives messages for Node B, as shown in the image below:
If the call goes well, the Source Process goes to a "wait for incoming message state". This state is held until Node B comes back with a response. When the incoming message state is finalized, the Source Process then moves on to some additional task or tasks.
If the call goes to an exception, then the Source Process directs to a "Handle error" state until an IT admin retries the Integration Link call.
ReceiveNodeARequest Integration Link
On the Node A messaging bus (which receives inbound requests from Node A), set a listener for the Node B queue.
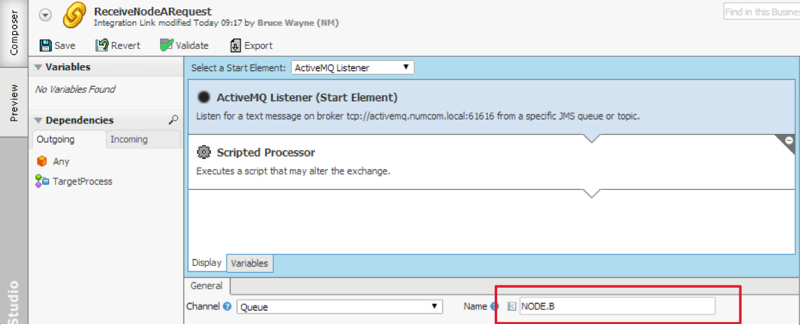
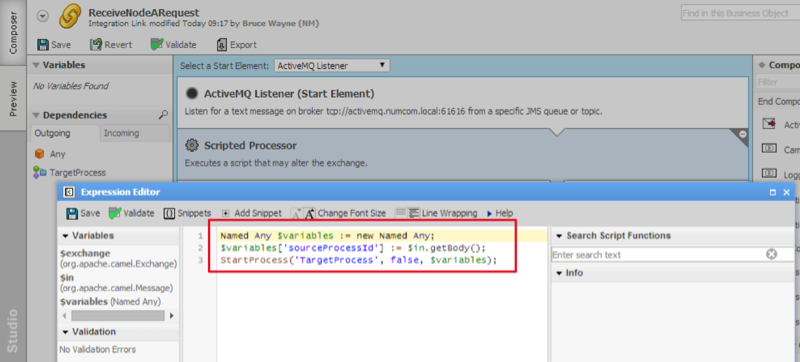
Once Node B receives a request from Node A, it executes a script to start a Process called Target Process:
Target Process
The Target Process allows the user on Node B to execute some actions. At some point in the Target Process, a response must be sent back to Node A. This response is again sent using an Integration Link.
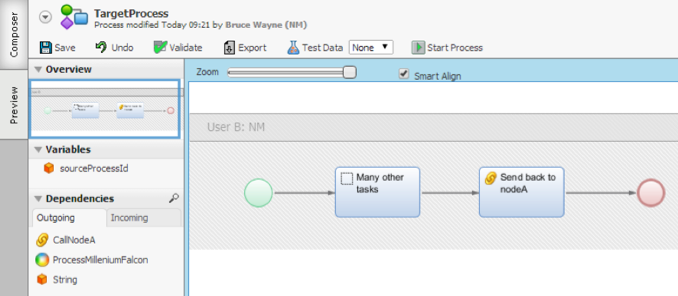
In order to know which process is to be notified on Node A, the Target Process needs a variable which contains the Source Process ID.
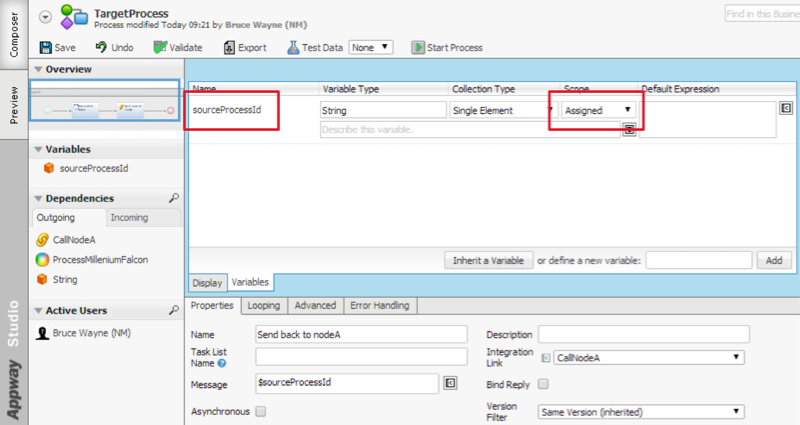
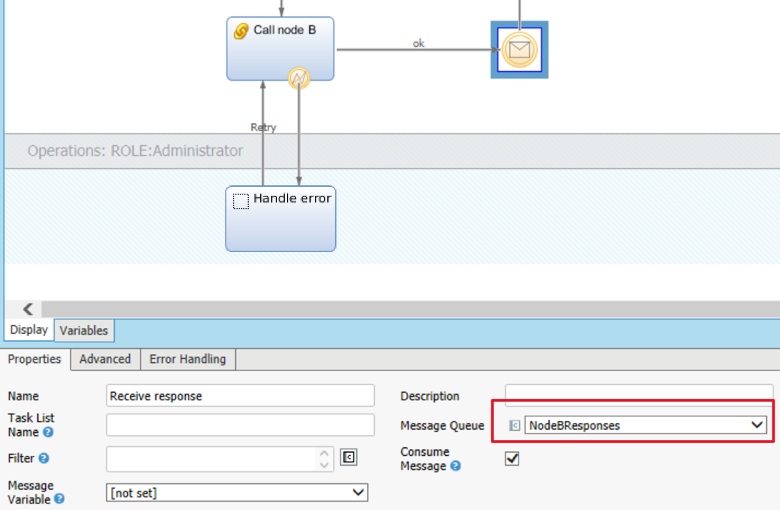
When the Target Process is finally ready to call back Node A via the Integration Link, it is important to set the processInstanceId of the process originating the call in the Send back to node A task, as shown in the image below:
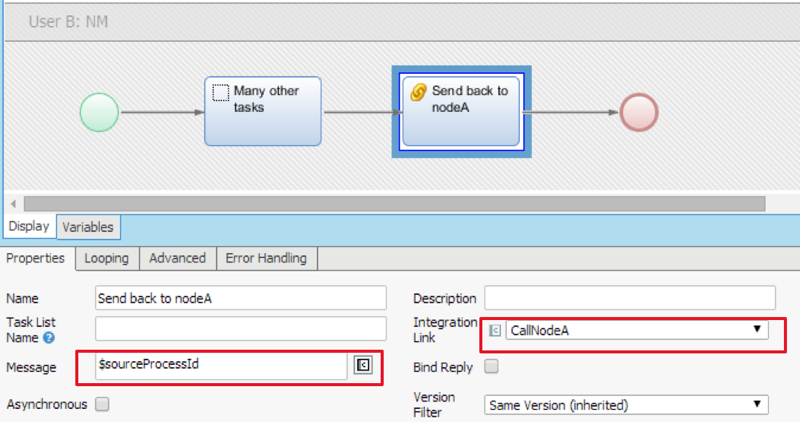
CallNodeA Integration Link
The calling Integration Link on Node B is very similar to the "CallNodeB" Integration Link on Node A. The difference is that "CallNodeA" has a "NODE.A" queue configured on the JMS/Active MQ bus:
ReceiveNodeBResponse Integration Link
The receiving integration link on Node A is similar to "ReceiveNodeARequest", but this time is listening for a different queue (NODE.A)
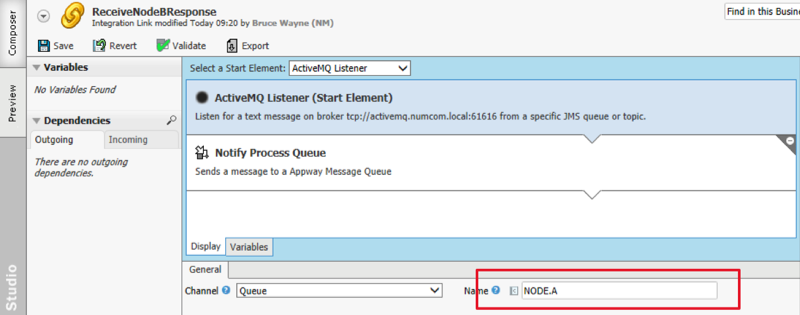
The receiving Integration Link notifies a process queue with the appropriate action. This is done by using the correct Message Queue, and by setting a target Workflow Instance ID as specified in the message body.
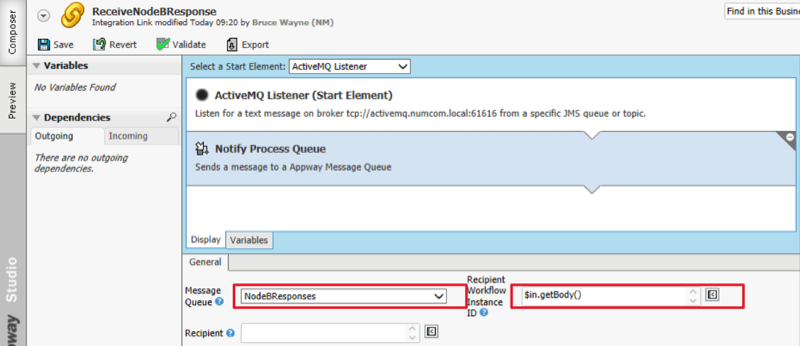
Source Process receives message
The intermediate receive message task in the Source Process waits for the appropriate message queue in FNZ Studio. Once the process gets the message published in the previous step, it can continue to the final set of tasks on Node A.
Monitoring Integration Link Load at Runtime
Problem
Is it possible to monitor Integration Link load at runtime?
How to determine whether the Integration Link thread pool size is appropriate for the system’s load?
Solution
You can monitor the message queue size of each Integration Link via JMX Beans, using JConsole, for example.
Figure 1 shows the current queue size of a "test" Integration Link, and the path to access it. The attributes ConcurrentConsumers and Timeout, visible in the list of attribute values as well as in the EndpointURI attribute, are configured in the Integration Link itself. In this example, these attributes are set to the default values of 5 concurrent consumers, and a timeout of 30 seconds.
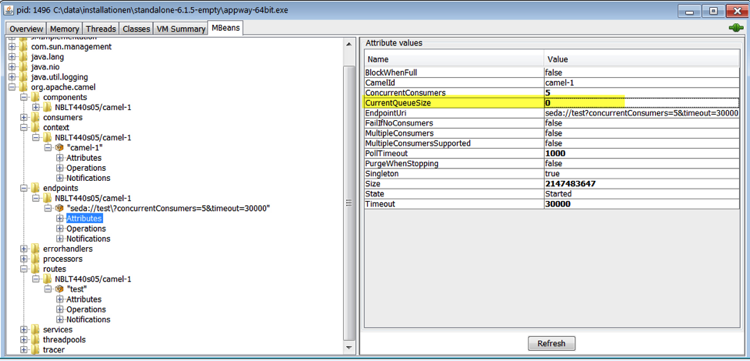
Figure 1: Message Queue Size
Should there not be enough threads in the Integration Link's thread pool to manage the load, the thread pool size can be adapted at run-time.
As the thread pool size is dynamically adapted based on the current load, we recommend increasing the attribute which defines the maximum number of threads: MaxPoolSize. The pool size is automatically decreased in case of a lower load.
Figure 2 shows the thread pool attributes, while Figure 3 shows how to change the MaxPoolSize attribute using the method setMaximumPoolSize.
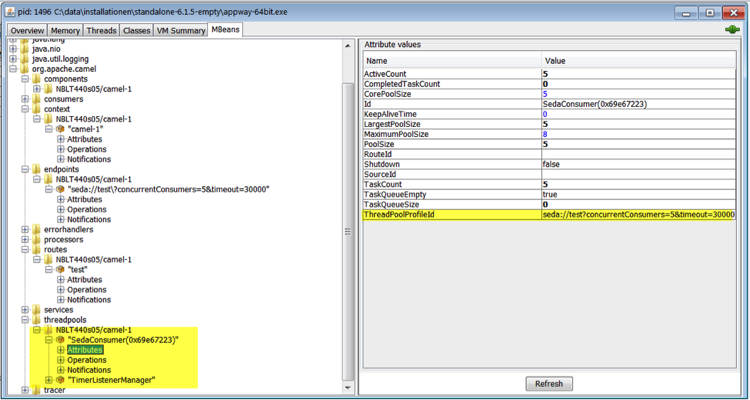
Figure 2: Thread pool attributes
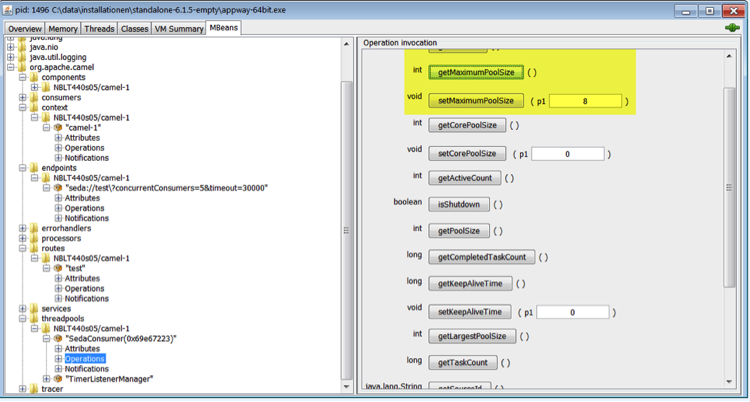
Figure 3: Operation "setMaxPoolSize"
Note: Changes to the size of an Integration Link thread pool via the JMX bean are not persisted. Restarting FNZ Studio resets the pool size to the value specified in the Integration Link Business Object
Executing Long-running Scripts in Parallel
Problem
I have a long-running script in my Process. I want to execute the script in parallel with other tasks. What's the best way to do that?
Solution
It may seem that the straightforward solution to executing the script in parallel with other tasks would be to use an "AND" gateway that transitions to all tasks that need executing in parallel.
The following screenshot illustrates this approach:
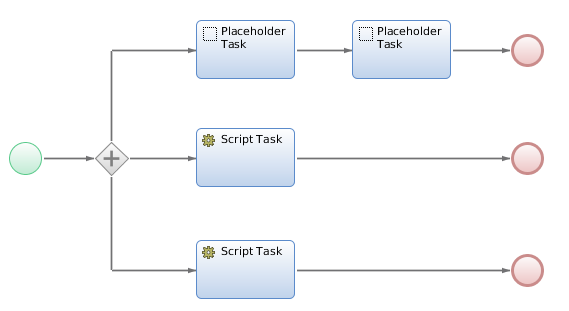
Obstacle #1: FNZ Studio process tasks are always executed sequentially, even if they are designed as parallel process tasks.
Let's try to execute some tasks using process engine threads. We can do this using a timer intermediate event with an execution time that is just a little bit in the future. An example expression could be:
TIMEADD(NOW(),'1s')
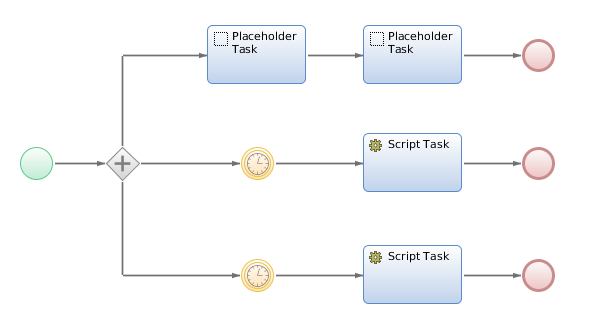
Obstacle #2: Even if the tasks are executed in different threads, we actually still end up with sequential execution.
Why? When executing a task, the executing thread requests a lock on the process instance. This is to ensure consistency of the process state, and of the process data. Because of that lock on the process instance, tasks executed by different threads still end up being executed in sequential order. Furthermore, you block the threads that have to wait for the locks to be released.
Note that the placeholder task (user interaction) does not have a preceding timer event, as that would redirect the user to the portal if no other user interaction token exists.
Overcoming Obstacles with the Integration Link
What we need to do is to take the long-running script out of the process context, and execute it independently.
We can only do this if the script can be executed on its own without having side effects on the process state, or on the process data - normally the case when executing a function. You pass the function arguments; the function then does some computation, and the result of that computation is returned to the caller.
Integration Links provide you with exactly that capability.
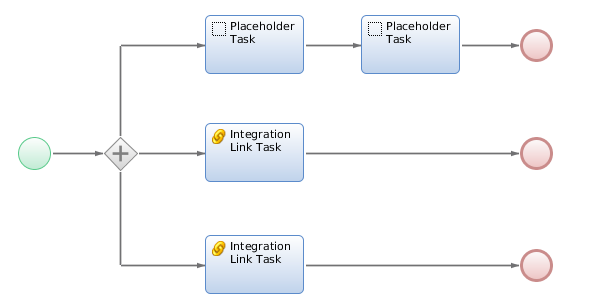
Integration Link Configuration
- The Integration Link component must be configured to use asynchronous execution
- The Integration Link task must have the "Asynchronous" flag checked
- If a value is returned by the Integration Link, use the "Bind Reply" flag to indicate that data must be bound back to the process
- Define the actual binding in the "Return Value Binding" property of the Integration Link task
The pattern works best if the Integration Link only executes a script function, and returns the resulting value. This can be implemented in a generic way, where the Integration Link defines the following assigned variables:

The implementation of the Integration Link is simple, because it only consists of the start element and a scripted processor.
The script used by the Scripted Processor to dynamically call a function looks like this:
java.util.ArrayList $args := new java.util.ArrayList;
ForEach Any $param In $params Do
$args.add(new com.nm.sdk.data.expeval.nodes.ConstantNode($param));
End
com.nm.sdk.data.expeval.MethodCallUtils.callScriptFunction($functionName, $args, EXECUTIONCONTEXT());
It is important to note that the script function must not use side effects such as:
- Modifying the entities that have been passed as parameters
- Accessing process state information
- Accessing any other information that is not passed as a parameter to the function