Process Instance Indexing
Process Instance Indexing improves the performance of filtering Process Instances or Process Tokens when using Inbox.
This feature can be enabled or disabled using the following property:
nm.cluster.processinstance.indexing.enabled = true
After changing this property, restart FNZ Studio in order for the changes to take effect.
The default value of this property is true.
Description
Data that is stored on a Process Instance or on a Process Token can be indexed so that it can be searched efficiently without having to iterate through all the Process Instances or Process Tokens in the system to execute a query.
A simple example would be how to speed up the filtering of the Process Instances that are assigned to a specific user.
Without using indexes, you have to:
- Go through all the Process Instances in the solution.
- Retrieve all Tokens for each Process Instance.
- Filter the Process Instances.
- Collect only those Process Instances which are assigned to the requested user.
This operation is expensive and the cost to do so increases with the number of Process Instances.
If the Process Instances assigned to the specific user are indexed, then the query becomes inexpensive and the execution time no longer increases linearly with the number of Process Instances in the solution.
Both transient and persistent Process Instances are indexed.
Indexing
How to Create an Index
Indexes can be created and deleted at runtime.
Use the following script function to create new indexes:
CreateProcessInstanceIndex(indexName, indexType, indexInfo)
The indexes are created with the status Inactive, meaning that they will not be used immediately for filtering, but rather that all the Process Instances that exist in the system are indexed. This indexing of Process Instances is triggered automatically after the index is created and when this process is finished, the new index is automatically used to resolve the requested filters.
The parameters of the script function that creates new indexes are the following:
IndexName – String value that describes the index. It has to be unique across all indexes and it can be used later on to retrieve information or different statistics about the index.
It cannot be blank and it cannot contain the following characters: '/' or '=' or '@'
IndexType can have one of the following values:
- ProcessInstanceMember – Indexes data stored on the Process Instance level.
The following members can be indexed:
- status – The status of a Process Instance.
- httpSessionId – The session ID bound to a Process Instance. To index all persistent and transient Process Instances, add the following Property Index:
CopyTo index only persistent Process Instances, add the following Property-Value Index:
CreateProcessInstanceIndex("PIHttpSessionIdIndex", "ProcessInstanceMember","httpSessionId")CopyCreateProcessInstanceIndex("PIHttpSessionIdNullIndex", "ProcessInstanceMember","httpSessionId=_PII_NULL_")
- ProcessInstanceAttribute – Indexes data stored as a Process Instance attribute.
Attributes of the following types are supported:
- String
- Boolean
- Integer
- Long
- Float
- Double
- DataMap (the keys)
- DataArray (DataValue instances for the simple types listed above)
- ProcessTokenMember – Indexes data stored on the Process Token level.
The following members can be indexed:
- status – The status of the Process Token.
- queueName – The user, group, or role name set as
queueNameon the Process Token. - processId – The Process Id of the Process Token.
- ProcessTokenAttribute – Indexes data stored as a Process Token attribute.
Attributes of the following types are supported:
- String
- Boolean
- Integer
- Long
- Float
- Double
- DataMap (the keys)
- DataArray (DataValue instances for the simple types listed above)
IndexInfo contains information about the data that will be indexed. It can contain the field that has to be indexed or the field and its value.
For example, if in the solution there is the need to search only Process Instances that have the status Active, then the indexInfo field contains both the field status and the value Active. It has the following structure: status=Active. Using this information, only the Process Instances that are active are indexed.
There can be multiple indexes on the same field, but using multiple values. For example, there can be an index for active Process Instances and another one for Process Instances that are in the Ready state.
When the value of a field is not known in advance or all the potential values have to be indexed, then only the field has to be specified.
For example, if all tokens that are assigned to different users have to be indexed, this field contains only the field name which is queueName.
Index Examples:
/* this will index all the Process Instances that are active. */
CreateProcessInstanceIndex("PIStatusActiveIndex", "ProcessInstanceMember", "status=Active")
/* this will index all the Process Instances that have an attribute called "city" and its value is "Zurich". */
CreateProcessInstanceIndex("PIAttributeCityZurich", "ProcessInstanceAttribute", "city=Zurich")
/* this will index all the Process Instances that have an attribute called "city" regardless of its value. */
CreateProcessInstanceIndex("PIAttributeCity", "ProcessInstanceAttribute", "city")
/* this will index all Process Instances that have someone assigned to one Process Token. */
CreateProcessInstanceIndex("PTQueueNameIndex", "ProcessTokenMember","queueName")
How to List Existing Indexes
Use the ListProcessInstanceIndexDefinitions() script function to return a list containing all the indexes that were previously defined.
How to Delete an Index
Use the DeleteProcessInstanceIndex(indexName) script function to delete an index together with all indexed data.
Index Structure
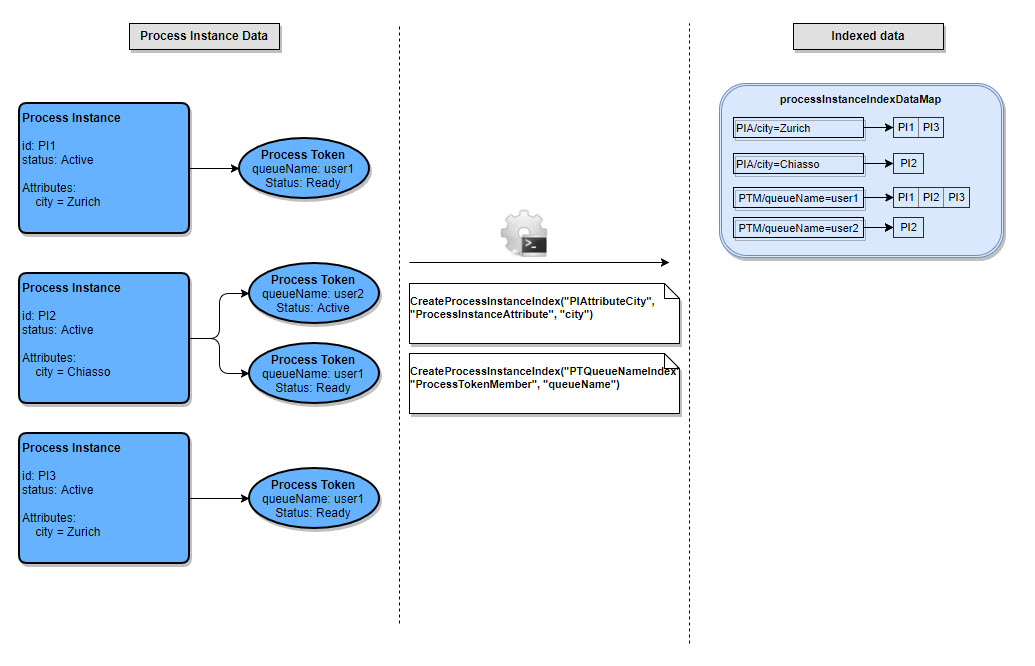
Filtering
Description
When no indexes are defined, filtering Process Instances using a Process Token Filter implies looping over all Process Instances in the system and checking if they match the given filter. Even though the looping is performed in a distributed manner and only checks the local Process Instances, it becomes very expensive when the number of Process Instances grows.
To be able to filter Process Instances using indexes, you can use the methods and the filters that have already implemented the lookup support.
Notes:
- Filtering using indexes returns a super set result of Process Instances IDs and not an exact result.
- Post-filtering must be applied to retrieve the exact result of the query.
- This post-filtering is provided out of the box when using functions that have already implemented the lookup support. E.g. `WORKLIST()` or `GetInboxWorkitems()` functions.
Example of filtering using indexes:
/* 1. Create some Process Instances that are assigned to a specific user. */
Integer $noPIs := 10;
For Integer $i := 0 Condition $i <= $noPIs Step $i := $i + 1 Do
StartProcess('IndexingTest');
End
/* 2. Create an index to be able to quickly retrieve the Process Instances assigned to users.*/
CreateProcessInstanceIndex("PTQueueNameIndex", "ProcessTokenMember","queueName")
/* 3. Retrieve the work items that are assigned to that specific user. This function will use the index defined at the previous step. */
/* This step can be run multiple times to get an idea of how fast the method execution is. */
String $userName := 'test';
Long $t1 := NOW().getTime();
String $result := WORKLIST($userName);
Long $t2 := NOW().getTime();
Double $time := $t2 - $t1;
PRINTLN(CONCAT('Time to retrieve the worklist: ', $time, 'ms'));
$result;
/* 4. Monitor the statistics to understand how the index is used. */
/* 5. (Optional) Delete the index and run again Step 3 to compare the method execution time when indexes are not used. */
DeleteProcessInstanceIndex("PTQueueNameIndex");
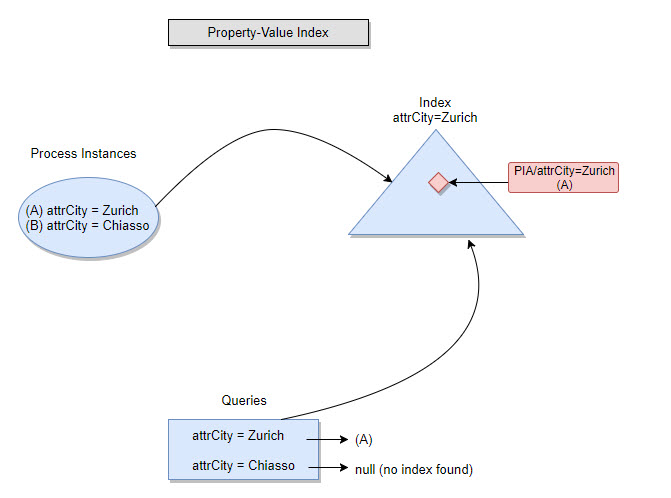
Filtering Using a Property-Value Index
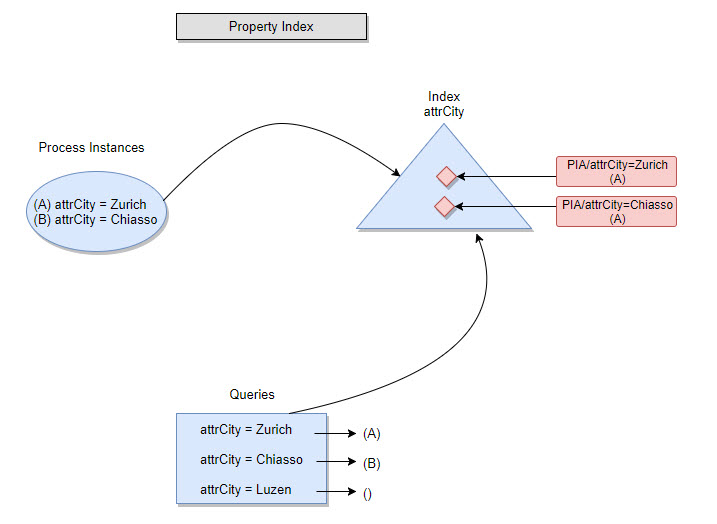
Filtering Using a Property Index
Statistics
To understand more about how indexes perform, you should monitor the statistics published under com.nm:type=Cluster,name=ProcessInstanceIndexingServiceInfo.
Properties Description
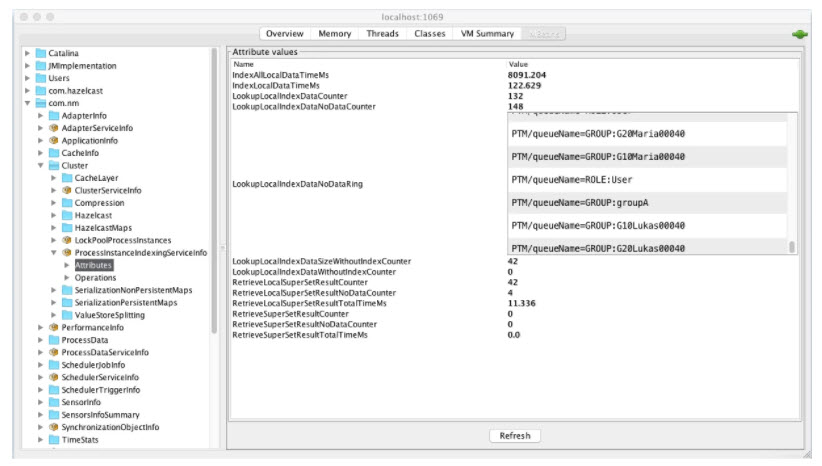
The available properties are:
- IndexAllLocalDataTimeMs – Represents the total time spent on looping over the Process Instances in the system and indexing them. Indexed data is not persisted, so every time FNZ Studio starts or when the Hazelcast topology changes (nodes are added or removed), all the Process Instances in the system are re-indexed and this attribute changes. This method returns local statistics and it has to be checked on every cluster node.
- IndexLocalDataTimeMs – Represents the total time spent on retrieving the needed data from a Process Instance and indexing it. This method returns local statistics and it has to be checked on every cluster node.
- LookupLocalIndexDataCounter – Counts the number of successful local index lookups (the requested indexed data was available). This is a local counter and it has to be checked on every cluster node.
- LookupLocalIndexDataNoDataCounter – Counts the number of local index lookups when the requested data was empty. For example, when all the users assigned to tasks are indexed, but the current query searches an inexistent user, this counter is increased. This is a local counter and it has to be checked on every cluster node.
- LookupLocalIndexDataNoDataRing – List containing the last 100 local entries when there was an index lookup, but the requested data was empty. It can be useful to understand if there are queries that are executed even though there is no data returned. This is a local counter and it has to be checked on every cluster node.
- LookupLocalIndexDataSizeWithoutIndexCounter – Counts the number of local index lookups when no index was available to be queried. This is a local counter and it has to be checked on every cluster node.
- LookupLocalIndexDataWithoutIndexCounter – Counts the number of local index lookups when no index was available to be queried. Very similar to the previous counter but this counter increases when an index was not active. This is a local counter and it has to be checked on every cluster node.
- RetrieveLocalSuperSetResultCounter – Counts the number of local successful queries that were executed using indexes. This is a local counter and it has to be checked on every cluster node.
- RetrieveLocalSuperSetResultNoDataCounter – Counts the number of local queries executed when the query could not be resolved using indexes. This is a local counter and it has to be checked on every cluster node.
- RetrieveLocalSuperSetResultTotalTimeMs – Total time spent on retrieving the result of a query using indexes on the current node. This is a local counter and it has to be checked on every cluster node.
- RetrieveSuperSetResultCounter – Counts the number of successful queries that were executed using indexes. This counter increases when a distributed query is executed.
- RetrieveSuperSetResultNoDataCounter – Counts the number of distributed queries executed when the query could not be resolved using indexes.
- RetrieveSuperSetResultTotalTimeMs – Total time spent on retrieving the result of a distributed query using indexes.
Operations Description
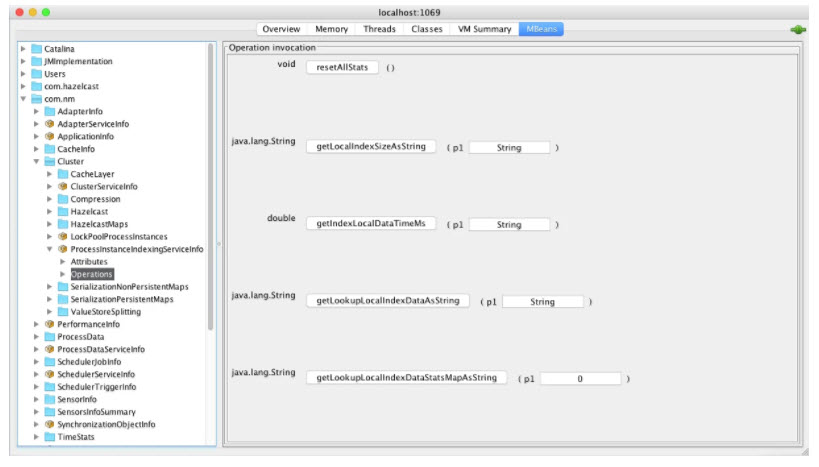
The available operations are:
resetAllStats() – Resets all statistics collected before.
getLocalIndexSizeAsString(String indexName) – Returns statistics about the size of the requested index.
The parameter of the method represents the index name that was used when the index was created.
This method returns local statistics and it has to be checked on every cluster node.
The information returned has the following structure:
IndexSizeInfo[
indexName=PTIndexQueueName,
totalSize=10500,
totalNoKeys=200,
avgKeySize=52.5,
largestKeysSet=[PTM/queueName=Edward00091@10 -> 100, PTM/queueName=Edward00092@10 -> 100]
]
It contains the following information:
- index name – The requested index name.
- totalSize – The total number of indexed Process Instances.
- totalNoKeys – The total number of keys in the map that keeps the indexed data.
- avgKeySize – The average key size which is the average number of Process Instances indexed per each key.
- largestKeySet – Set with 10 entries containing the largest keys of the index together with their size.
getIndexLocalDataTimeMs(String indexName) – Represents the total time spent on indexing data for the requested index. This is a local counter and it has to be checked on every cluster node.
getLookupLocalIndexDataAsString(String indexName) – Returns lookup statistics of the requested index.
The parameter of the method represents the index name that was used when the index was created.
This method returns local statistics and it has to be checked on every cluster node.
The information returned has the following structure:
LookupIndexInfo[
totalLookupTimeMs=0.521,
totalNoOfHits=132,
totalSize=660
]
It contains the following information:
- totalLookupTimeMs – Total time spent on retrieving indexed data for the requested index.
- totalNoOfHits – Total number of lookups for data on the requested index.
- totalSize – Total size of the data returned when there was a lookup on one of the keys of the requested index.
getLookupLocalIndexDataStatsMapAsString(Integer noReturnedEntries) – Returns a map of lookup statistics for all existing indexes.
The parameter defines how many entries this method should return. Since the collected data can be quite large, retrieving it all might be expensive. That is why only a limited number of entries is returned and this number has to be between 1 and 10000.
This method returns local statistics and it has to be checked on every cluster node.
The information returned has the following structure:
{
PTM/queueName=Maria00046=LookupIndexInfo[totalLookupTimeMs=0.013,totalNoOfHits=4,totalSize=20], PTM/queueName=Maria00047=LookupIndexInfo[totalLookupTimeMs=0.013,totalNoOfHits=4,totalSize=20], PTM/queueName=Maria00050=LookupIndexInfo[totalLookupTimeMs=0.038,totalNoOfHits=8,totalSize=40]
}
It contains a list of index keys and for each key, it contains a LookupIndexInfo object containing statistics about that index key.
- totalLookupTimeMs – Total time spent on retrieving indexed data for the current index key.
- totalNoOfHits – Total number of lookups for data on the current index key.
- totalSize – Total size of the data returned when there was a lookup on one of the keys of the current index key.