Value Store Splitting
Introduction
Value Store Splitting is a tuning feature which improves the performance of managing Value Stores, especially of large ones.
Background The Appway platform manages Process Data and its associated Business Data in two separate containers:
- Process Instance – Process data required to drive a Process
- Value Store – (Business) data gathered throughout a Process
Value Stores can potentially grow very large (e.g. in cases where a lot of data is gathered). Large Value Stores are very costly in terms of memory, network, and CPU, as Appway is based on a clustered architecture. This means that data access and update operations require data to be fetched from and stored back to its 'home' node, and in some cases also to and from the persistent storage. On the other hand, updating requires writing to the 'home' node, persistent storage, and backup. Fetch and update operations happen for each request:
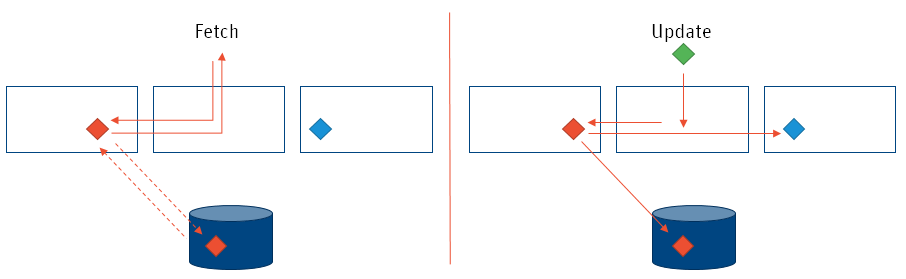
The larger the Value Store, the more costly these fetch and update operations become. Example Value Store sizes:
- Retail onboarding with 1 client, 1-2 accounts: ~250-500KB
- KYC as a part of private bank onboarding: ~500KB-1MB
- Private bank onboarding with 6 parties, legal entities, and around 10 Products: 2-10MB
Solution Value Store Splitting addresses the performance issues caused by large Value Stores by allowing Appway to fetch and update only the data that is required as part of a specific request:
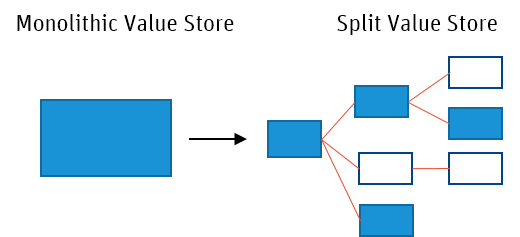
Splitting monolithic Values Stores into many smaller parts allows for far more efficient fetch and update operations:
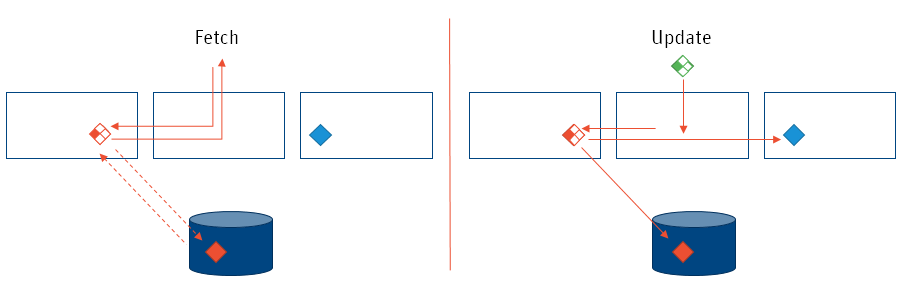
The benefits of using Value Store Splitting can be summarized as:
- Reduced memory consumption
- Only relevant parts of the Value Store are kept in memory (cache layers).
- Reduced network traffic
- Only required/updated data has to be passed between cluster nodes.
- Only updated data has to be sent to persistent storage.
- Improved response time
- Value stores are only partially loaded, which is faster.
- Improved caching
- Fetched Value Store parts are cached until changed.
- Without Value Store Splitting, all data was evicted from the cache upon change.
General Information
Activating Value Store Splitting
Value Store Splitting can be enabled or disabled at runtime by setting the following configuration properties:
nm.cluster.persistence.valuestores.splitting.enabled
nm.cluster.persistence.valuestores.splitting.process.ids
The default value of the property nm.cluster.persistence.valuestores.splitting.enabled is set to false: you need change it to true to enable the feature.
However, changing this property is not enough, as you need to specify the Processes for which the Value Stores should be split. To do so, create a comma-separated list of such Processes and set it as the value of the nm.cluster.persistence.valuestores.splitting.process.ids property. Consider that:
- The default value of this property is an empty String, meaning that no Value Store is split by default.
- To split all the Value Stores for all Processes, set the property to *.
For further information on enabling Value Store Splitting, see the Migrating to Value Store Splitting section.
Assignment Policy
When assigning Data Value instances to Named or Indexed collections, Appway uses an "assign by reference" policy for legacy and backwards-compatibility reasons. For new installations, we recommend switching this policy to "assign by value". By using this policy, Data Value instances are no longer shared among multiple Named or Indexed collections, but rather, a separate Data Value is maintained.
To enable the recommended "assign by value" policy, set the following two properties to false:
nm.script.compatibility.named.collection.assign.dv.byref = false
nm.script.compatibility.indexed.collection.assign.dv.byref = false
When changing this policy for existing Solutions, the complete Solution needs to be re-tested. This is required because Data Value instances might have been shared unintentionally so that an update in one place could also update the Data Value in another place.
For further information on enabling the recommended "assign by value" policy with existing Process Data, see the Migrating to Value Store Splitting section.
Value Store Structure
A Value Store contains a map of scopes and each of these scopes contains a map of so-called Data Entities which wrap the actual data that needs to be stored.
A Data Entity which is connected to a Value Store can have links to any other Data Entity in that Value Store. This means that all the Data Entities of a Value Store represent a graph.
The type of a Data Entity depends on the value that it wraps:
-
Data Value – contains a simple data type, e.g. Java classes or Appway Primitive Types.
-
Data Object – contains an instance of a Data Class Business Object defined in Appway. Data Class Business Objects can be marked as Autonomous or Non-autonomous by changing the Autonomous setting. The default value of this setting is
true, meaning all instances of a Data Class are by default autonomous. An autonomous Data Class represents a class that has self-contained instances that make sense to be stored independently.- Example 1: a Data Class called 'Person', which consists of many attributes of a person (age, address etc.). It can be considered an autonomous structure.
- Example 2: A Data Class called 'Shape' that points to another Data Class called 'Point', which holds only 2 coordinates of a point. The 'Point' Data Class can be considered to be non-autonomous and its instances can be stored together with the instances of 'Shape' class.
There are no strong limitations about which Data Classes must be marked as autonomous and which must be non-autonomous. In general, it is recommended to mark Data Classes that have small instances as non-autonomous since the overhead of storing these small instances can be bigger than the advantage of having a very small Value Store.
A Data Object wraps all the data in a map called 'properties'. These properties are other Data Entities that wrap the real data that needs to be stored. Since Data Objects are lazy loaded, by default they have an empty map of properties even though they have actual data stored. When a Data Object is in this state, it is called "unresolved". When a property in the map is accessed for the first time, all the properties of that Data Object are loaded and it is "resolved".
-
Data Array – contains an array of other Data Entities
-
Data Map – contains a map of other Data Entities
The Value Store Splitting feature introduces a new way of managing Data Entities: autonomous Data Entities can be stored and retrieved independently of the Value Store which results in improved performance.
Behavior
If you are not using Value Store Splitting, the whole Value Store is retrieved, de-serialized, changed, serialized and saved every time a part of the data in the Value Store is modified. This process is very expensive, especially for Value Stores containing a lot of data.
Enabling Value Store Splitting improves this behavior. In this case, every time a Value Store is modified, only the Data Entities which were modified have to be persisted. Also, the Value Store data is lazy loaded, meaning that the autonomous Data Entities are loaded only when they are accessed for reading or modification.
This process happens transparently.
The decision whether a Value Store should be split or not, however, is taken only once at the very beginning of a new Process Instance. If Value Store Splitting is enabled for the new Process (see configuration properties), the Value Store is split, otherwise the Value Store is persisted as a whole.
To support Value Store Splitting, a new distributed map was added which contains Data Entities that are connected to a Value Store. It is called dataEntitiesMap.
There is also a new distributed map called valueStoreToDataEntitiesMap that is used to more efficiently access the Data Entities connected to a Value Store. It has an entry for each Value Store, containing references of all Data Entities connected to the current Value Store and which were detached and saved in the dataEntitiesMap.
To decide if a Data Entity is autonomous or not, the model has to be checked. The checked model version is the one used to start the Process Instance.
Restrictions
There are some restrictions with regards to which Value Stores can be split:
-
Persistent Value Stores Only persistent Value Stores are split. For non-persistent Value Stores, the old behavior applies.
-
Invalid Links Since the Data Entities represent a graph and any Data Entity can point to any other Data Entity, there can be some situations where invalid links are generated.
For example, when a non-autonomous Data Entity which is stored inside an autonomous Data Entity points to a different non-autonomous Data Entity which is contained inside another autonomous Data Entity.
Cases of this type are referred to as "invalid links" and the Value Store is not split if at least one such invalid link is found. -
Exposed Data Entities If any Data Entity from within a Value Store is also stored outside of a Value Store (using the same Java object reference), then this Data Entity must no longer be split and the value Store is merged back into a whole, non-split Value Store. This protects the second reference (to the Data Entity outside of the Value Store).
Example: If a Script Task in a Process stores a Process variable (a variable defined in the Process) into the Application Cache usingCacheStore(), then this Process variable is merged back into the Value Store the next time the Value Store is committed.
Notes: Avoid directly storing a Process variable outside of the Process. If you need to store the state of a Process outside of the Process, clone that data (i.e. explicitly detach it from the Value Store) and store it then.
Script Functions
ValueStore:Merge Function
The ValueStore:Merge function can be used for already split Value Stores.
It merges Data Entities which were detached back into the Value Store. The references of the Data Entities are removed and the Value Store is not split again regardless of the Value Store Splitting status.
The method returns a Boolean value. It returns true if the Value Store has been merged successfully. It always merges the detached Data Entities regardless if Value Store Splitting is enabled or not.
ValueStore:MergeAllLocalValueStores Function
The ValueStore:MergeAllLocalValueStores function can be used to mark all existing local Value Stores as non splittable so that they are not affected by the Value Store Splitting feature when it is enabled. Moreover, it merges all the Data Entities that were detached back into Value Stores.
This function, when executed, should always be wrapped by the ExecuteDistributed function to be applied on all cluster nodes (see also the Activating Value Store Splitting section).
Starting from Appway 10.1.4, the execution uses a throttler ensuring that no more than 100 Value Stores are merged per second. This helps avoid overloading the system, e.g. the write-behind queue and/or JVM Garbage Collection.
Moreover, and also starting from Appway 10.1.4, the ValueStore:MergeAllLocalValueStores Script Function also prints the progress for every 1000 Value Stores that have been processed to the system log. Log messages look as follows: Still merging local Value Stores: countProcessed=3000.
ValueStore:DebugNonSplittable Function
The ValueStore:DebugNonSplittable function identifies the reasons why a Value Store cannot be split and points you to invalid links and related data structures in the Process.
Note: As mentioned in Restrictions section, Value Stores cannot be split if they contain invalid links.
As a parameter, this function receives a Process Instance ID and determines if the corresponding Value Store is splittable:
- If the Value Store is splittable, it returns the following string: "Value Store is splittable".
- If Value Store is not splittable, it returns a string stating that the Value Store is not splittable together with the Data Entity that generates the invalid links and all the paths that lead to that data entity.
As an example, consider the following data structures:
Person: {name:String, address:Address}– Autonomous Data EntityAddress: {street:String, city:String, country:String}– Non-autonomous Data Entity
Also consider a simple Process that has two variables defined: somePerson and someAddress.
$somePerson := new Person;
$someAddress := new Address;
A Process Instance belonging to the above Process will have a splittable Value Store containing two variables:
- The variable
$somePersonwill be detached since it is autonomous - The variable
$someAddresswill be saved together with the Value Store since it is non-autonomous.
If later on in the Process there is the following assignment, the Value Store won't be splittable anymore since the Data Entity $someAddress (that was saved together with the Value Store) is now referenced inside an autonomous Data Entity:
$somePerson.address := $someAddress
In this case, the ValueStore:DebugNonSplittable script function can be used to identify the issues. Its output will be similar to the following one:
Value Store is not splittable because the following data entity is referenced through the following paths:
Entity: $someAddress(Address/1495436999173)
Path: *$someAddress(Address/1495436999173)*
Path: $somePerson(Person/1495436999172)->*$someAddress(Address/1495436999173)*
This output shows that there is a non-autonomous Data Entity that is referenced through multiple paths in the given Value Store. These paths are useful to identify the variables defined in the Process and the underlying data structures and to change them accordingly.
Further features of the output are:
- The Data Entities are printed according to the following pattern: type / id of the Data Entity.
- If the Data Entity is defined in the Process as a variable, it will also contain the name of the variable.
- The Data Entity that generates invalid links will be printed surrounded by "*" to highlight it.
The fix for the above Process would be to remove the variable $someAddress and use the $somePerson.address object instead.
Note: Starting from Functions extension 6.1.6, if a Value Store contains more than one Data Entity that generates invalid links, a compound of all issues found is shown. nFor previous versions of the extension, only the first issue identified is printed. After the first issue is fixed, the `ValueStore:DebugNonSplittable` can be used again to identify any possible further issues.
ValueStore:AnalyzeIfSplittable Function
The ValueStore:AnalyzeIfSplittable function analyzes the content of split Value Stores.
Parameters
- As a required parameter, this function receives the id of the Process Instance for which the corresponding Value Store should be analyzed.
- This function also receives an optional parameter of type Double, which represents the size of the smaller threshold used to group the Data Objects in the Value Store. The larger threshold used is 10 times the small one, so there are three size ranges. The default smaller threshold is 10 KB.
Return type The return type of the function is String and it contains the following information:
- The size of the Value Store without detached Data Objects
- The number of detached Data Objects
- The size of the Value Store merged together with the detached Data Objects
- For every Data Class, the number of instances of that Data Class, the total size and the average size of the instances
- For every size range, the number of Data Objects with the size in that range and the total size
Migrating to Value Store Splitting
-
Before enabling Value Store Splitting, you should mark all existing Value Stores as non splittable. This ensures that existing Value Stores are not split accidentally. You can execute the following code snippet to do that:
Copy
ExecuteDistributed(ValueStore:MergeAllLocalValueStores()) -
Now you are ready to enable Value Store Splitting for the selected Processes. In this example, we enable Value Store Splitting for
Solution:ProcessAandSolution:ProcessB:Copy
nm.cluster.persistence.valuestores.splitting.enabled = true
nm.cluster.persistence.valuestores.splitting.process.ids = Solution:ProcessA, Solution:ProcessB -
New instances of Solution:ProcessA and Solution:ProcessB are now automatically split.
-
(Recommended) Although, there are no further steps required, it is recommended that you review the Data Model. Inspect the existing Data Classes and check the setting of the Autonomous option. This option is set to
trueby default, but it can make sense to change it tofalsefor Data Classes that have very small object instances. Check the Data Object section for examples. -
(Recommended) When assigning Data Value instances to Named or Indexed collections, Appway uses an "assign by reference" policy for legacy and backward-compatibility reasons. We recommend switching this policy to "assign by value". By using this policy, Data Value instances are no longer shared among multiple Named or Indexed collections, but rather a separate Data Value is maintained. This also helps avoid the "invalid link error" issue.
To understand what effect those two properties have on your Solution, enable the following Logger before switching to the new policy in Appway Studio (System Maintenance > Logging > Loggers):
Copycom.nm.sdk.data.expeval.CollectionPointer = INFOIf this Logger does not exist in your Appway Studio, this means that no log messages of this type have been logged since the last restart. In this case, your Solution is not affected by the change of policy and no further testing is required - simply enable the new policy. If this Logger exists, on the other hand, after changing the log level to INFO, look for log messages like the following:
CopyAssigning a non-immutable, non-transient DataValue to a collection.To enable the recommended "assign by value" policy, set the following two properties to false:
Copynm.script.compatibility.named.collection.assign.dv.byref = false
nm.script.compatibility.indexed.collection.assign.dv.byref = falseWhen changing this policy for existing Solutions, the complete Solution needs to be re-tested. This is required because Data Value instances might have been shared unintentionally so that an update in one place could also update the Data Value in another place.
Value Store Splitting Studio Modules
You can check Value Store Splitting through two modules in Appway Studio:
- Value Stores (Solution Maintenance > Processes > Value Stores)
- Data Entities (Solution Maintenance > Processes > Value Stores > Data Entities)
Value Stores
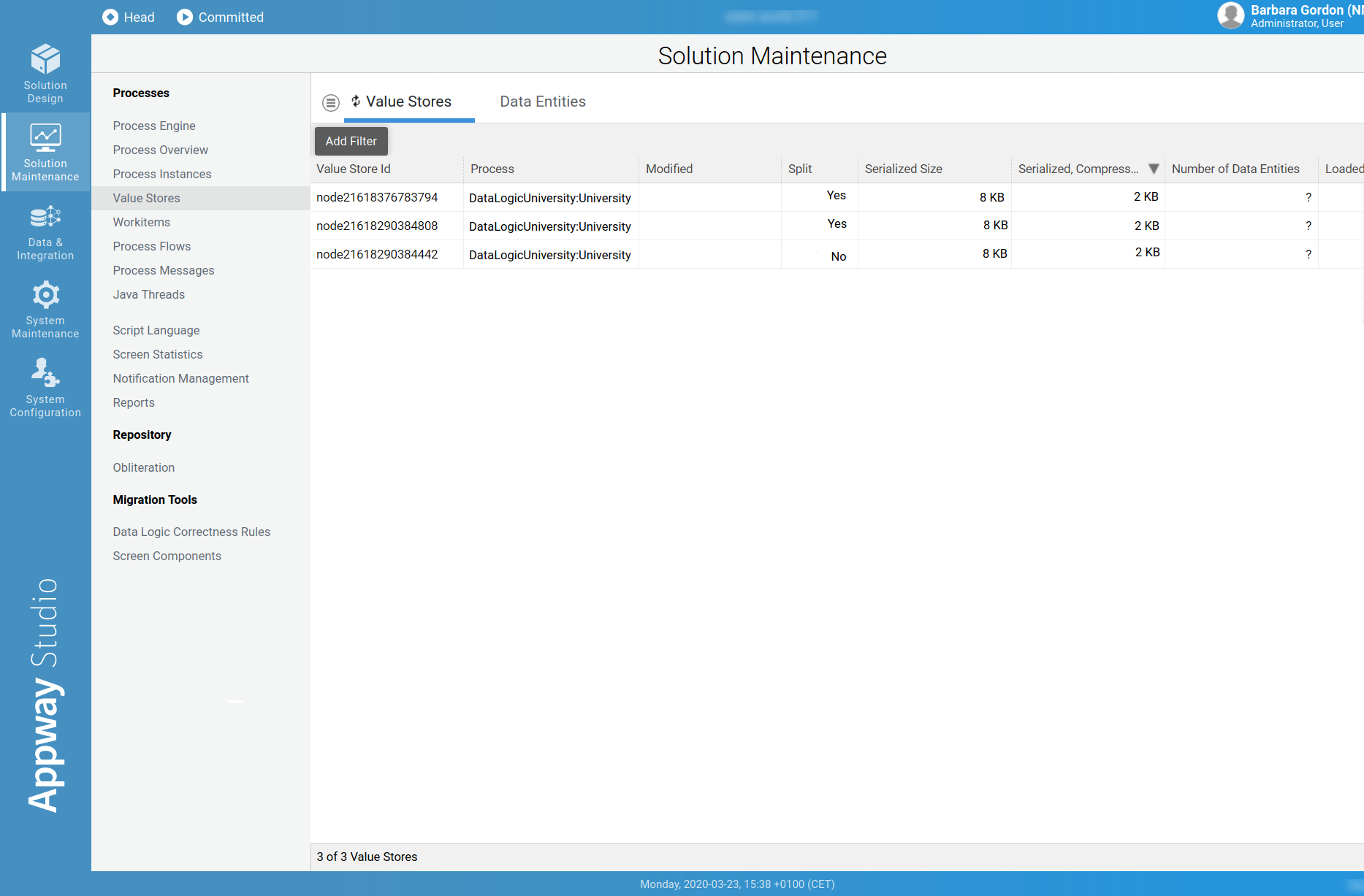
This module allows monitoring Value Stores. Following is a description of each column:
- Value Store Id: The ID of the Value Store.
- Process: The top-level Process which created this Value Store.
- Modified: The last modification timestamp of the Value Store (if empty, then this information is not currently available in the Value Store metadata index. The index is updated when the Value Store is modified for the first time after Cluster startup.)
- Split: Indicates whether a Value Store is split or not.
- Serialized Size: The size of the Value Store before placing it into the distributed map.
- Serialized, Compressed Size: The size of the Value Store in the distributed map.
- Number of Data Entities: Number of Data Entities in a Value Store.
- Loaded Ratio [%]: The percentage of data loaded per request in comparison to the total size of the Value Store.
- Changed Ratio [%]: The percentage of data changed per request in comparison to the total size of the Value Store.
Data Entities
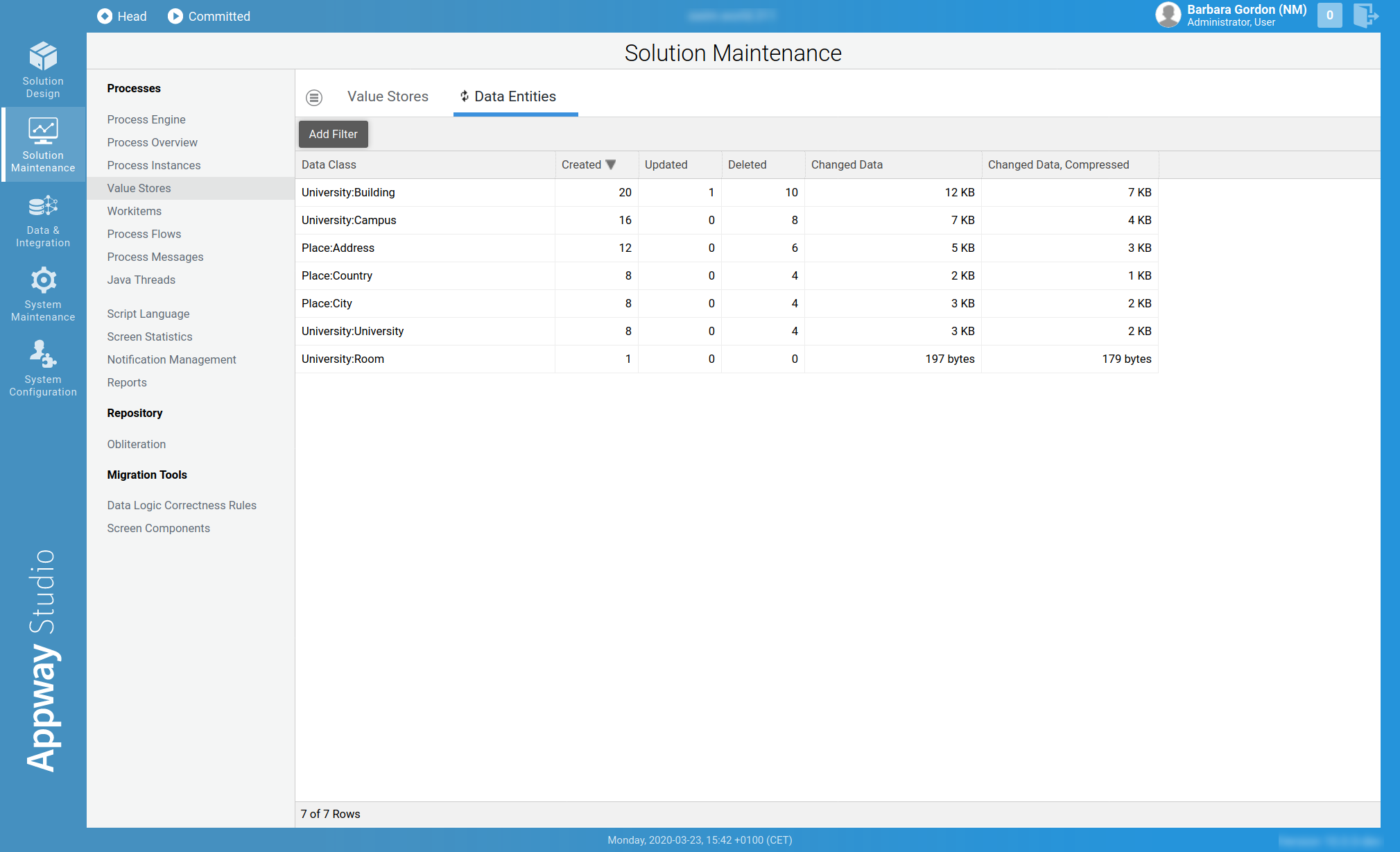
This Studio module provides information per Data Class. This is specially useful when looking for Data Classes that require a considerable amount of system resources, e.g. Data Classes that are very often created or updated, or Data Classes that produce a considerable amount of changed data. Following is a description of each column:
- Data Class: The Data Class to analyze.
- Created: Number of instances of this Data Class that have been created.
- Updated: Number of instances of this Data Class that have been updated.
- Deleted: Number of instances of this Data Class that have been deleted.
- Changed Data: Amount of data that has been modified and stored due to this Data Class, e.g. in Create or Update operations.
- Changed Data, Compressed: Changed Data shown after compression.
Monitoring
Appway provides a way to monitor the performance of Value Store Splitting.
The system exposes some useful metrics through JMX technology. Use a JMX client and navigate into the MBeans section to the folder com.nm.Cluster.ValueStoreSplitting, where you can access these metrics.
The metrics are divided into two categories:
- ValueStoreSplittingServiceInfo – Contains statistics about load and store DataObject operations. See more information.
- DataEntityStoreImplInfo – Contains statistics about changed, cloned, and loaded data entities. See more information.
All the metrics are per node and they reset when the node reboots.
ValueStoreSplittingServiceInfo
The ValueStoreSplittingServiceInfo section has the following attributes:
- LoadOperationCount – Number of performed load operations
- LoadOperationThreadCount – Number of threads currently using the load operation
- LoadOperationTime – Total time of load operations (in milliseconds)
- StoreOperationCount – Number of performed store operations
- StoreOperationThreadCount – Number of threads currently using the store operation
- StoreOperationTime – Total time of store operations (in milliseconds)
The function resetStats can be used to reset all the previous statistics.

DataEntityStoreImplInfo
The DataEntityStoreImplInfo section has the following attributes:
- CloneOperationCount – Number of clone operations
- CloneOperationTime – Total time of clone operations (in milliseconds)
- AverageCloneOperationTime – Average time for a clone operation (in milliseconds)
- LoadedDataEntitiesCount – Number of loaded data entities update operations
- AverageLoadedDataEntitiesRatio – Average number of loaded data entities compared with the overall number of data entities in the corresponding Value Store
- ChangedDataEntitiesCount – Number of changed data entities update operations
- AverageChangedDataEntitiesRatio – Average number of changed data entities compared with the overall number of data entities in the corresponding Value Store
The function resetStats can be used to reset all the previous statistics.

Functions
Three functions are available:
- resetStats – Resets all the statistics in DataEntitityStoreImplInfo.
- getAverageChangedDataEntitiesPerVsRatio – Provide a Value Store Id for the function to return the average number of changed data entities for the specified Value Store. The statistic for the Value Store might not be found, if the ratio is less than 0.1. However, this number does not need to be monitored, since it indicates that, on average, less than 10% of the data is changed for that Value Store. This means that the solution is well designed and it leverages the new feature.
- getAverageLoadedDataEntitiesPerVsRatio – Provide a Value Store Id for the function to return the average number of loaded data entities for the specified Value Store. As for the previous function, the statistic for the Value Store might not be found if the ratio is less than 0.1.
Questions & Answers
Question 1: Invalid link error when linking to an Indexed or Named Collection
Question: I get a invalid link error if there is a reference from Object A to an Indexed or Named Collection in Object B. Is this because an Indexed or Named Collection is non-autonomous?
Answer: Yes, Indexed and Named Collections are non-autonomous and you can, therefore, only link to them if they are inside the current autonomous Data Class instance.
If you need to reference Indexed or Named Collections outside of the current autonomous Data Class instance, we suggest creating a wrapper object around the collection and link to this instead.
For example, if you have a Named Collection of persons that you want to link to from outside of the current autonomous Data Class instance, you can create a new Data Class called GroupOfPersons which contains the Named Collection and link to that instead.